Au cœur de l’intelligence artificielle, les algorithmes d’apprentissage automatique ont révolutionné la manière dont les données sont analysées. Ces algorithmes permettent aux ordinateurs de tirer des conclusions, de faire des prédictions et d’apprendre des expériences passées sans être explicitement programmés. Chacun d’eux a ses propres caractéristiques et est adapté à des types spécifiques de problèmes. Décortiquons ensemble les principales catégories d’algorithmes d’apprentissage automatique et comprenons comment chacune d’elles fonctionne.
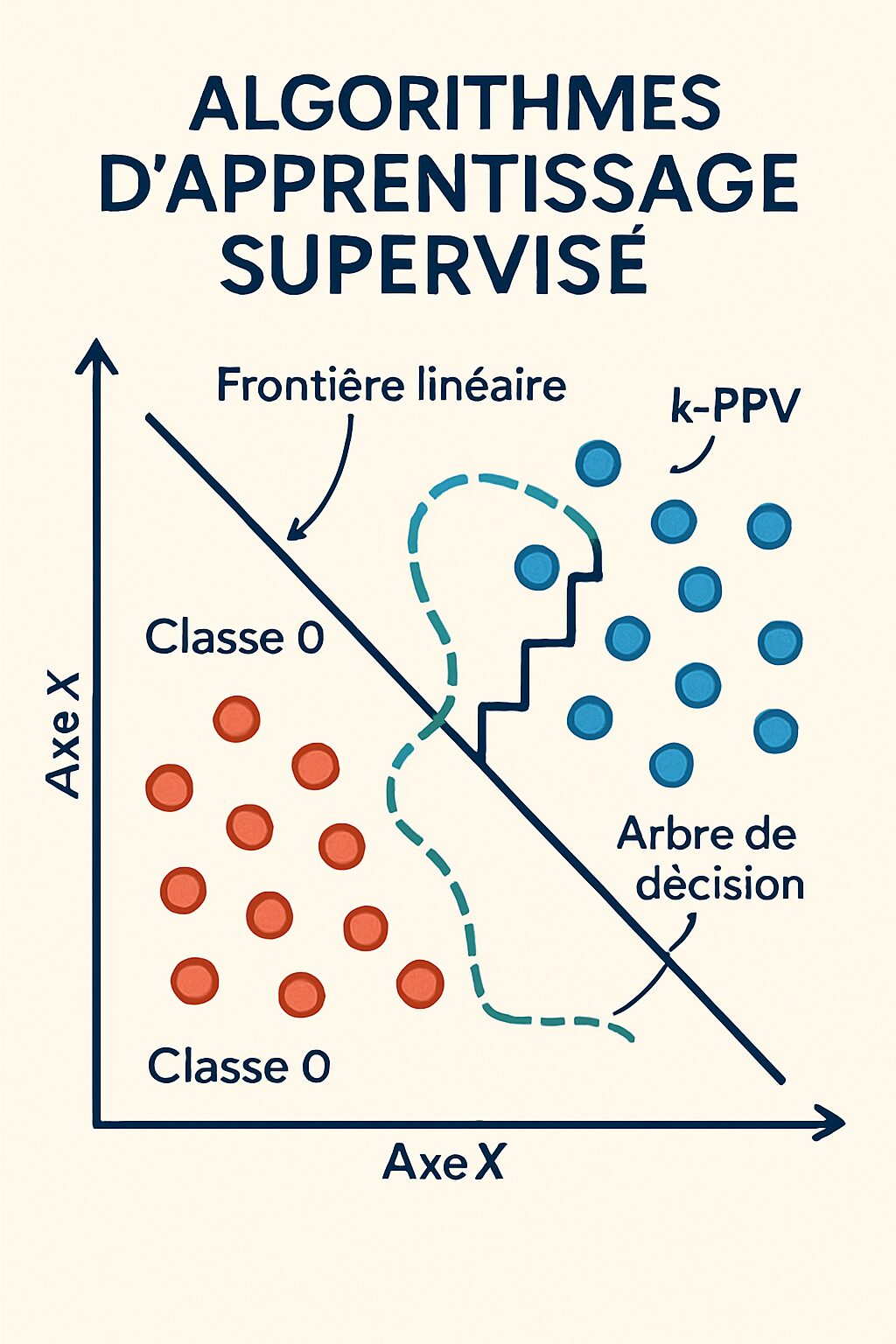
Algorithmes d’apprentissage supervisé : le guide des modèles prévisibles
L’apprentissage supervisé se base sur la notion de données étiquetées. Imaginez un professeur qui montre une scène à ses élèves, annotant chaque élément. Ici, les données étiquetées servent de référence pour entraîner les modèles d’apprentissage. Ces algorithmes cherchent à prédire un résultat en se basant sur les données déjà connues. Les applications sont multiples, allant de la classification d’emails en spam ou non spam à la prédiction des prix immobiliers.
Les principaux algorithmes d’apprentissage supervisé :
- Régression Linéaire : Idéal pour prédire une valeur continue. Par exemple, estimer le prix d’une maison en fonction de sa superficie et de sa localisation.
- Régression Logistique : Bien qu’elle porte le nom de régression, elle est utilisée pour des classifications. Parfait pour les situations binaires, comme classer un courriel en spam ou non.
- Atrees de Décision : Ils fonctionnent comme un arbre où chaque nœud représente un attribut. Par exemple, déterminer si un patient doit subir un examen en fonction de ses symptômes.
- Forêt Aléatoire : Un ensemble d’arbres de décision qui améliore la précision de la prédiction en agrégant les résultats de plusieurs arbres.
- K-Plus Proches Voisins (KNN) : Un algorithme de classification basé sur la proximité des données. Plus un nouvel exemplaire est proche des autres, plus il est probable qu’il appartienne à la même catégorie.
Pour mieux comprendre le fonctionnement de ces algorithmes, prenons l’exemple d’un projet étudiant. Supposons qu’un groupe d’étudiants souhaite créer un modèle qui prédit le succès académique basé sur des facteurs tels que la présence en classe ou les notes des tests. Grâce à un algorithme de régression linéaire, ils peuvent établir une fonction qui relie ces variables aux performances académiques. Au fil du temps, et après avoir ajusté les paramètres, le modèle pourrait fournir des prévisions de réussite pour de nouveaux étudiants.
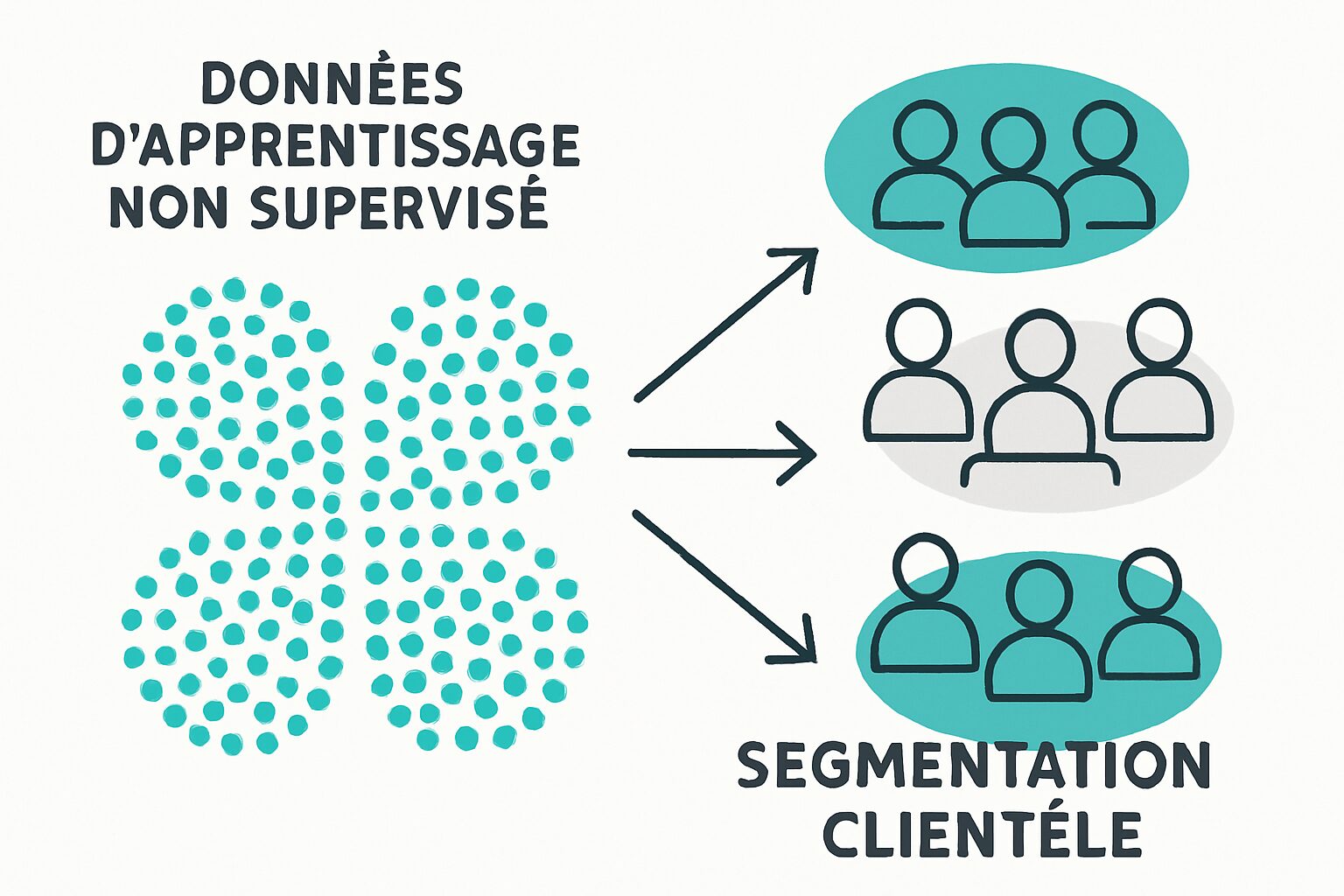
Algorithmes d’apprentissage non supervisé : à la recherche de modèles cachés
L’apprentissage non supervisé se concentre sur l’analyse de données non étiquetées, permettant aux algorithmes de découvrir des structures sans intervention humaine. Ces algorithmes doivent identifier les motifs ou les regroupements dans les données. Un bon exemple serait l’analyse de comportements d’achat pour segmenter une clientèle. Au lieu de dire à l’algorithme quoi chercher, il explore les données pour créer des groupes naturels.
Les principaux algorithmes d’apprentissage non supervisé :
- K-Means : Un algorithme de clustering qui divise les données en ‘k’ groupes basés sur leurs caractéristiques. Par exemple, segmenter les clients d’une plateforme e-commerce en fonction de leurs comportements d’achat.
- Analyse en Composantes Principales (ACP) : Un algorithme de réduction de dimension qui transforme les données en un ensemble de variables unifiées, facilitant l’identification de modèles sans perdre d’information cruciale.
- Regroupement Hiérarchique : Crée une arborescence de clusters, utile pour visualiser les relations entre différentes catégories, par exemple dans le cadre de l’analyse de text.
Imaginez un restaurant qui désire évaluer les préférences alimentaires de sa clientèle sans information préalable. Grâce à K-Means, l’établissement peut identifier des groupes de clients ayant des choix similaires, permettant ainsi d’adapter son menu de manière stratégique. Les données fournies par les commandes peuvent révéler des modèles fascinants !
Algorithmes d’apprentissage semi-supervisé : la meilleure des deux mondes
Les algorithmes d’apprentissage semi-supervisé combinent les data sets étiquetés et non étiquetés. C’est une approche prisée lorsque l’acquisition de données étiquetées est coûteuse ou complexe. Ce type d’apprentissage aide l’algorithme à mieux généraliser à partir de quelques données étiquetées tout en s’appuyant sur une plus grande quantité de données non étiquetées.
Principes de fonctionnement :
- Initialement, un modèle est entraîné sur un petit nombre de données étiquetées pour établir une première version du modèle.
- Ensuite, ce modèle est utilisé sur un plus grand ensemble de données non étiquetées pour prédire les étiquettes. Ces nouvelles prédictions peuvent à leur tour être ajoutées à l’ensemble de données d’entraînement.
- Ce processus itératif se poursuit, améliorant continuellement la précision du modèle.
Une application concrète pourrait se voir dans le secteur médical. Considérons un cas où seulement un petit échantillon de maladies rares a été étiqueté. En utilisant l’apprentissage semi-supervisé, les chercheurs peuvent tirer parti des données non étiquetées sur d’autres cas similaires pour améliorer leurs prévisions sur les maladies non étiquetées, augmentant ainsi leurs chances de découverte.
Apprentissage par renforcement : l’apprentissage basé sur les récompenses
L’apprentissage par renforcement repose sur un système de récompenses et de pénalités. Imaginez un chien qui apprend un tour : à chaque fois qu’il obéit à l’ordre, il reçoit une friandise. Ce type d’algorithme apprend par essais et erreurs, cherchant à maximiser les récompenses tout en évitant les erreurs. Contrairement aux autres types d’apprentissage, il ne nécessite pas de données historiques étiquetées, ce qui le rend unique.
Caractéristiques des algorithmes d’apprentissage par renforcement :
- Environnement dynamique : L’algorithme interagit avec un environnement, adaptant ses actions en temps réel.
- Politique d’apprentissage : Définit comment l’agent agit en fonction de l’état actuel. Par exemple, dans un jeu vidéo, la stratégie peut changer en fonction du niveau rencontré.
- Récompenses : L’agent reçoit des récompenses en fonction des actions entrepris, pour encourager les comportements positifs.
Une application fascinante est celle des voitures autonomes. Ces véhicules utilisent des algorithmes d’apprentissage par renforcement pour naviguer en toute sécurité dans des environnements complexes. Ils apprennent à optimiser leurs trajets à chaque interaction avec leur environnement, prenant des décisions basées sur les récompenses de sécurité et d’efficacité.
Choisir le bon algorithme : les facteurs clés à considérer
Lorsqu’il s’agit d’appliquer des algorithmes d’apprentissage automatique, plusieurs facteurs doivent être pris en compte. Le choix de l’algorithme dépend souvent de la nature du problème, de la qualité des données disponibles, et des résultats souhaités. Un bon data scientist doit identifier les exigences de son projet avant de faire un choix éclairé.
Critères de sélection :
- Type de données : S’agit-il de données étiquetées ou non étiquetées ? Cela influencera le choix entre un apprentissage supervisé ou non supervisé.
- Complexité du problème : Un problème de classification simple peut être résolu par un arbre de décision, alors qu’un problème plus complexe nécessitera une méthode comme les réseaux neuronaux.
- Disponibilité des ressources : Les algorithmes comme les réseaux neuronaux requièrent souvent plus de puissance de calcul et de données que les méthodes plus simples.
En somme, comprendre les types d’algorithmes d’apprentissage automatique permet aux entreprises et aux data scientists d’exploiter le plein potentiel des données. En explorant ces catégories, chacun peut mieux s’armer pour réussir dans l’univers dynamique de l’intelligence artificielle.