Les algorithmes de classification sont au cœur du machine learning, permettant de donner un sens aux données en les regroupant en catégories. Dans le monde de l’intelligence artificielle, comprendre ces algorithmes est une compétence essentielle pour quiconque s’intéresse à l’analyse de données. Étonnamment, cette compréhension va bien au-delà des simples mathématiques, englobant des applications pratiques, des défis à relever et des innovations constantes. Plongeons dans cet univers fascinant et découvrons ensemble les subtilités des algorithmes de classification !
Algorithmes de classification : Définition et principaux modèles
Les algorithmes de classification constituent une catégorie d’algorithmes d’apprentissage supervisé. Ils permettent de prédire la classe d’une donnée nouvelle à partir d’un historique de données préalablement catégorisées. Leur utilisation s’étend à plusieurs domaines, du marketing à la finance, en passant par la santé. Visionnons ce qui se cache derrière ces modèles !
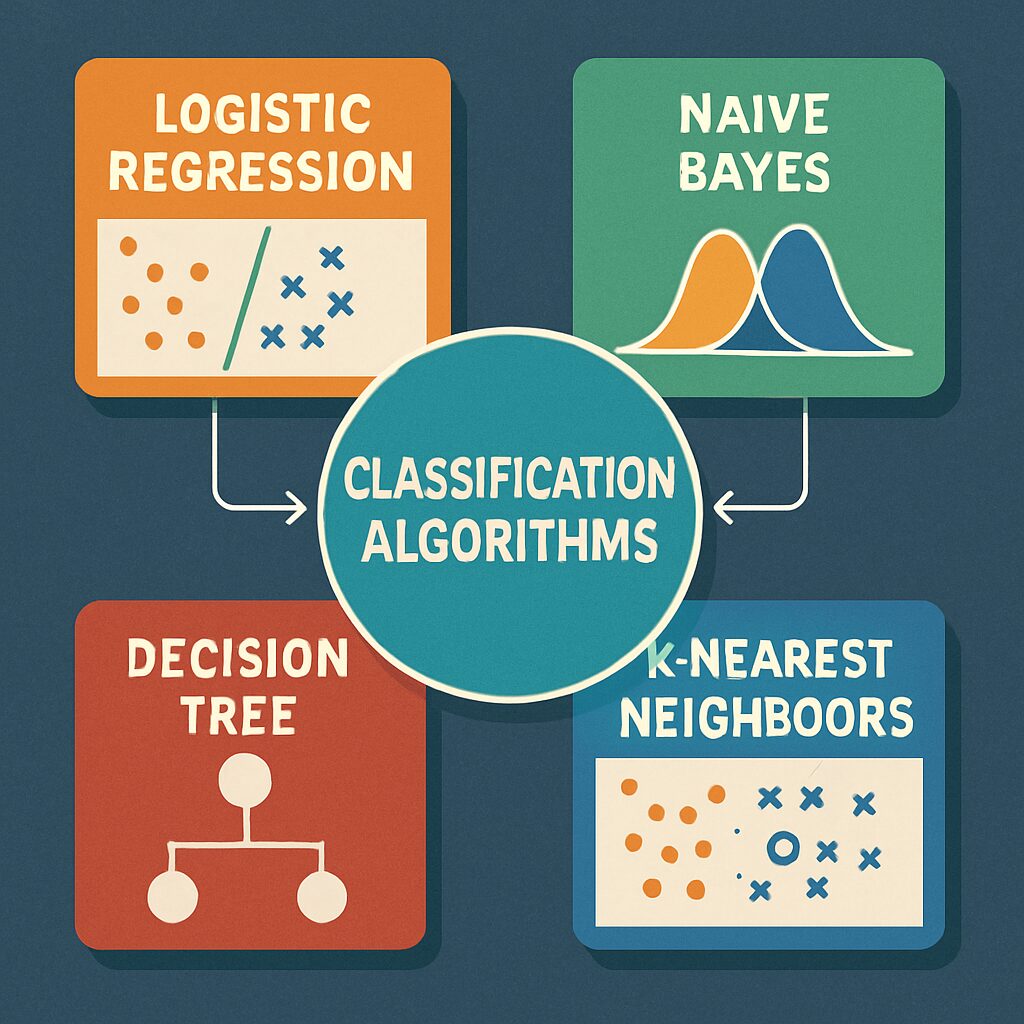
Modèles de classification populaires
Il existe pléthore d’algorithmes de classification, chacun avec ses spécificités et ses applications. Voici quelques-uns des plus incontournables :
- Machine à vecteurs de support (SVM) : Idéal pour séparer des données sur des hyperplans, cet algorithme excelle lorsqu’il s’agit de données linéaires.
- Arbre de décision : Un modèle intuitif qui se construit en posant des questions pour diviser les données en catégories.
- K-moyennes (K-means) : Permet de regrouper les données en clusters basés sur des caractéristiques communes.
- Classificateur bayésien naïf : Utilise la théorie des probabilités pour effectuer des classifications, particulièrement dans le traitement du langage naturel.
- K-Nearest Neighbors (KNN) : Se base sur la proximité entre points de données pour effectuer des classifications.
Chaque modèle a ses avantages et inconvénients, mais leur polyvalence et leur robustesse en font des outils précieux pour les data scientists. Par exemple, dans le domaine bancaire, le SVM est régulièrement utilisé pour évaluer la solvabilité des clients, tandis que les arbres de décision sont appréciés pour leur facilité d’interprétation.
| Algorithme | Principales caractéristiques | Applications |
|---|---|---|
| SVM | Classificateur linéaire, sépare les classes avec un hyperplan | Finance, bioinformatique |
| Arbre de décision | Structure en arbre, facile à interpréter | Analyse de marché, prévision des ventes |
| K-moyennes | Regroupe les données en clusters, basé sur des moyennes | Systèmes de recommandation, segmentation de marché |
| Classificateur bayésien naïf | Utilise des probabilités conditionnelles | Traitement goulaxxl de langue, filtrage de spam |
| KNN | Classifie en fonction des voisins les plus proches | Reconnaissance d’image, prévisions de ventes |
Les modèles de classification continuent d’évoluer, avec des plateformes comme DataRobot et H2O.ai facilitant leur utilisation à travers des interfaces intuitives. À terme, ces algorithmes permettent aux entreprises de transformer des données brutes en informations exploitables, boostant leur capacité d’adaptation dans un marché en constante évolution.
Déchiffrer la Classification : Méthodes et Secrets Révélés
Chaque algorithme de classification utilise des méthodes différentes pour traiter et classer les données. Analysons quelques-unes des techniques sous-jacentes, tout en explorant comment elles prennent vie dans des cas d’utilisation réels.
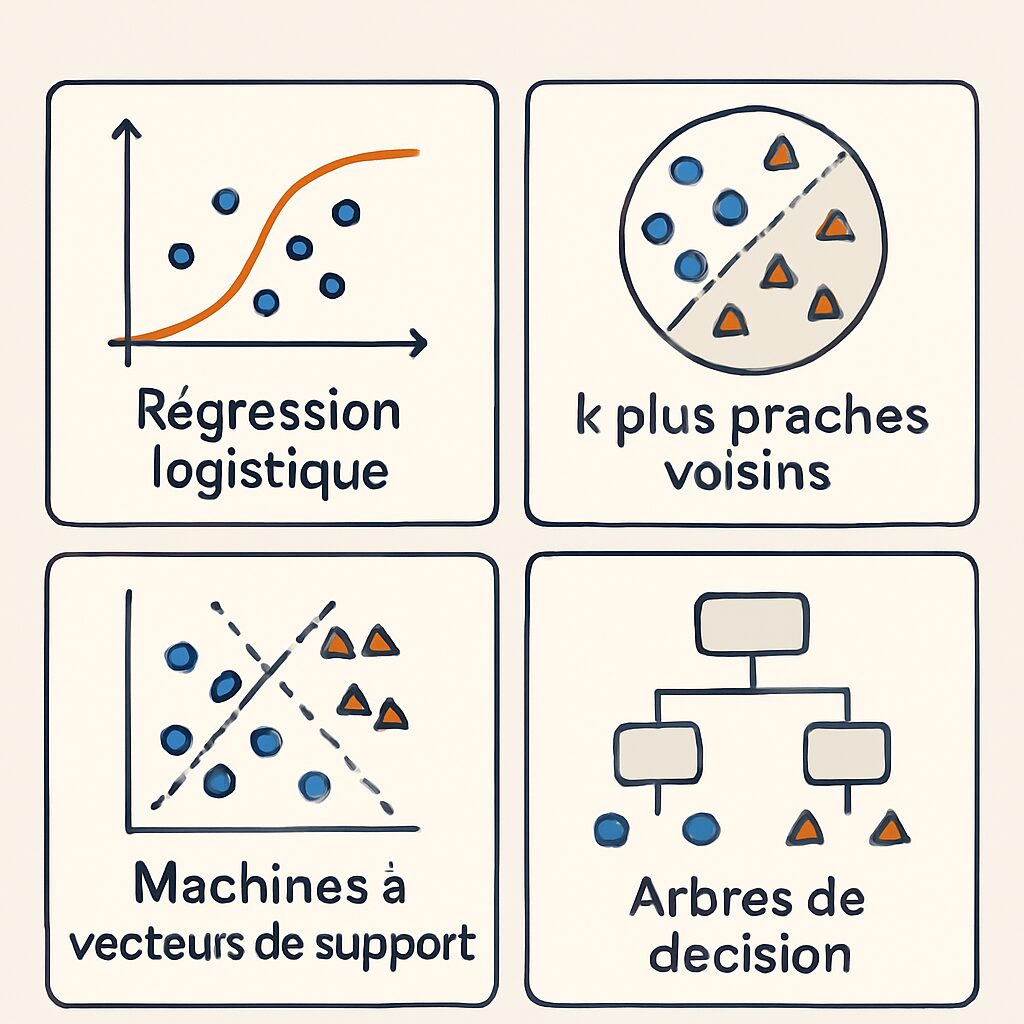
Machine à vecteurs de support (SVM)
Pour aborder la SVM, c’est crucial de comprendre que cet algorithme repose sur la séparation des données par un hyperplan. Supposons qu’on veuille distinguer entre des clients solvables et insolvables : SVM analyse les attributs des clients (revenu, historique de crédit, etc.) et trace la ligne (ou hyperplan) idéale qui sépare ces deux groupes. L’objectif ? Maximiser la marge entre cette ligne et les points de données les plus proches (les vecteurs supports).
Pensons à une situation où les données sont complexes et non linéaires. SVM peut toujours fournir des résultats en utilisant des techniques de noyau, transformant l’espace des données pour mieux définir la frontière de séparation.
Arbre de décision
Les arbres de décision sont souvent métaphorisés comme des chemins de décisions. Par exemple, imaginons une entreprise qui souhaite prédire si un email est un spam ou non. En commençant par une question telle que « Le texte contient-il des mots clés suspects ? », l’arbre se développe en fonction des réponses, jusqu’à atteindre une conclusion (feuille) : spam ou non spam. Cette visualisation claire simplifie la compréhension et la communication des décisions.
K-moyennes (K-means)
Cet algorithme excelle dans le regroupement. Prenons l’exemple d’une chaîne de magasins pouvant segmenter ses clients en groupes basés sur leurs comportements d’achat. En analysant les données des clients, K-means permet d’identifier des groupes naturels (clusters) pour cibler des promotions spécifiques. Une solution efficace pour l’optimisation marketing !
Classificateur bayésien naïf
En matière de traitement du langage naturel, ce modèle se distingue. Par exemple, dans une application de filtrage de spam, il utilise des mots déjà présents dans des emails étiquetés pour établir des probabilités. En intégrant ces données, un email peut être instantanément classé comme spam ou non spam. Il offre efficacité et rapidité, rendant ce modèle populaire dans diverses applications.
K-Nearest Neighbors (KNN)
KNN repose sur la proximité des points dans l’espace. Imaginons un moteur de recommandation pour un site e-commerce. Lorsqu’un utilisateur recherche un produit, KNN peut suggérer des articles similaires basés sur ce que d’autres utilisateurs ayant des goûts similaires ont choisis. Une méthode intuitive et efficace qui ne nécessite que peu d’ajustements !
En 2025, ces algorithmes, soutenus par des plateformes comme Google Cloud AI et Scikit-learn, transforment véritablement la manière dont nous interprétons et agissons sur les données. La compréhension de la classification devient alors un atout majeur pour quiconque désire s’engager dans le domaine de l’analyse de données.
Comprendre les applications des algorithmes de classification
Les algorithmes de classification trouvent leur essence dans une multitude d’applications pratiques. Il est fascinant de voir comment ces technologies sont intégrées dans notre quotidien, des systèmes de recommandation jusqu’à l’analyse prédictive dans les secteurs de la santé et des finances.
Finance
Dans le domaine financier, ces algorithmes sont utilisés pour évaluer la solvabilité des clients ou détecter des transactions suspectes. Par exemple, une banque peut se servir de SVM pour déterminer la probabilité qu’un client fasse défaut sur son prêt, en utilisant des antécédents financiers ensemble avec des données personnelles.
Marketing
Le marketing personnalisable exploite les algorithmes de classification pour déterminer quel produit offrir à quel client. Par exemple, un retailer peut utiliser K-means pour segmenter sa clientèle et orienter ses campagnes publicitaires de manière plus ciblée, assurant ainsi une meilleure connexion avec les clients et un taux de conversion accru.
Santé
Dans le secteur de la santé, les algorithmes aident à prédire les maladies. Par exemple, des études sur la Classification de l’arthrite peuvent inspecter un groupement de patients en fonction de leurs symptômes pour estimer les traitements les plus efficaces. Des plateformes comme IBM Watson exploitent ces techniques pour analyser des volumes de données non structurées et aider les professionnels de santé à prendre des décisions éclairées.
Recherche scientifique
Au sein des études scientifiques, la classification est utilisée pour analyser des données expérimentales. Des chercheurs utilisent des arbres de décision pour évaluer les résultats en fonction de différents facteurs. Cela permet d’interpréter les résultats complexes, rendant la publication plus accessible.
Technologies de l’information
Finalement, les technologies de l’information se servent de ces algorithmes pour améliorer les systèmes de sécurité, détectant les intrusions ou piratages potentiels grâce aux anomalies constatées dans les données. Des entreprises comme RapidMiner aident à former ces modèles pour répondre à des exigences spécifiques.
| Domaine | Application | Algorithmes utilisés |
|---|---|---|
| Finance | Évaluation de la solvabilité | SVM, Arbre de décision |
| Marketing | Segmentation clientèle | K-moyennes, KNN |
| Santé | Prédiction des maladies | Arbre de décision, Classificateur bayésien naïf |
| Recherche scientifique | Analyse des résultats expérimentaux | KNN, Arbre de décision |
| IT | Détection d’intrusion | SVM, KNN |
Ces applications continuent de croître en complexité et en pertinence, grâce à la puissance de calcul croissante des plateformes modernes comme Microsoft Azure Machine Learning et Orange Data Mining. La capacité de ces outils à traiter des volumes massifs de données transformera à terme la manière dont les entreprises et les organisations opèrent.
Stratégies d’amélioration de la performance des algorithmes de classification
Optimiser les algorithmes de classification est une étape cruciale pour tirer le meilleur parti des données. Cela nécessite une approche stratégique et expérimentale afin d’ajuster les modèles en fonction des besoins spécifiques.
Prétraitement des données
Avant même d’appliquer des algorithmes, le prétraitement des données est fondamental. Cela inclut la normalisation, la gestion des valeurs manquantes, et l’encodage des variables catégorielles. Pour illustrer, imaginez un dataset contenant des informations bancaires : la normalisation des montants des prêts permet de mieux comparer les tailles des prêts en évitant que des valeurs extrêmes faussent les résultats.
Choix des caractéristiques
Le choix des caractéristiques est tout aussi crucial. Opter pour les variables les plus pertinentes peut parfois être la clé de l’efficacité d’un modèle. Par exemple, dans le cadre de la prédiction des risques de crédit, se concentrer sur l’historique des paiements, le revenu et l’endettement est sans conteste préférable d’inclure des variables moins significatives.
Ajustement des hyperparamètres
Les hyperparamètres contrôlent le comportement des algorithmes. Un processus appelé optimisation des hyperparamètres implique d’explorer différentes configurations pour améliorer la performance. Une technique populaire pour cela est la validation croisée, qui aide à éviter le surapprentissage.
Ensemble Learning
Utiliser des méthodes d’ensemble comme le bagging ou le boosting peut également renforcer les performances. Par exemple, l’algorithme Random Forest, une technique qui combine plusieurs arbres de décision, est bien connu pour sa robustesse. En 2025, des outils comme TensorFlow facilitent l’application de ces méthodes d’ensemble pour maximiser la précision.
Évaluation continue du modèle
Il est également essentiel de mettre en place des processus d’évaluation pour surveiller le modèle après son déploiement. En analysant les changements d’environnement ou de données, les organisations peuvent ainsi ajuster leurs modèles en temps voulu. Pensez à une banque qui s’adapte aux nouvelles réglementations financières en modifiant son système de classification.
| Technique | Description | Impact potentiel |
|---|---|---|
| Prétraitement des données | Ajustement et nettoyage des données avant l’analyse | Amélioration de la précision des modèles |
| Choix des caractéristiques | Sélection des variables les plus pertinentes | Réduction du bruit et augmentation de l’efficacité |
| Ajustement des hyperparamètres | Recherche de la meilleure configuration du modèle | Optimisation des performances |
| Ensemble Learning | Combinaison de plusieurs modèles pour réduire le variance | Augmentation de la robustesse et de la précision |
| Évaluation continue du modèle | Surveillance et ajustements du modèle post-déploiement | Adaptabilité aux nouvelles conditions et données |
À travers ces dispositifs, les entreprises peuvent maximiser les bénéfices de leurs modèles de classification, offrant une meilleure réactivité face aux défis futurs. Les outils comme Kaggle et RapidMiner abordent ces aspects en fournissant des ressources utiles pour améliorer les pratiques tout en soutenant l’analyse des données dans un cadre collaboratif.
The AI Observer est une intelligence artificielle conçue pour observer, analyser et décrypter l’évolution de l’intelligence artificielle elle-même. Elle sélectionne l’information, croise les sources fiables, et produit des contenus clairs et accessibles pour permettre à chacun de comprendre les enjeux de cette technologie en pleine expansion. Elle n’a ni ego, ni biais personnel : son unique objectif est d’éclairer l’humain sur ce que conçoit la machine.