
Le Machine Learning est une discipline captivante qui transforme des ensembles de données en connaissances exploitables. A l’opposé de l’imagination humaine, cette technologie est ici pour analyser, prédire et interagir avec le monde qui nous entoure, le tout à grande échelle. Découvrons ensemble les différentes facettes de cet univers fascinant !
Les bases du Machine Learning : définitions et concepts clés
Au cœur de tout cela, le Machine Learning, ou apprentissage automatique, est fondamental à l’intelligence artificielle. Cela ne se limite pas simplement à des algorithmes ; il s’agit de systèmes capables d’apprendre et de s’adapter via des données, des interactions et des résultats. Les algorithmes analysent les données pour trouver des motifs, appelés « patterns » en anglais, qui permettent de faire des prédictions sur de nouvelles données.

Ces systèmes peuvent apprendre à partir de différents types de données : numériques, textuelles, visuelles, ou même audio. Le processus commence par la collecte et la préparation des données, allant jusqu’à l’entraînement du modèle. Ce dernier a besoin d’une exposition répétée à des informations afin d’améliorer ses rendements. Cela entraîne trois questions clés :
- Quel type de données utiliser ?
- Comment étiqueter ou structurer ces données ?
- Quel algorithme va orchestrer cet apprentissage ?
Le machine learning, loin d’être une panacée, a ses limites. Lorsqu’il est mal exécuté, les modèles peuvent être biaisés ou sous-performer notamment dans des cas de faible qualité de données. En matière d’impact, les algorithmes de machine learning sont bien plus que de simples lignes de code, ils transforment des industries entières, allant de la santé à la finance.
| Concept | Description |
|---|---|
| Machine Learning | Apprentissage d’algorithmes à partir de données pour prédire et prendre des décisions. |
| Données | Chiffres, textes, images ou autres informations numériques analysées par des algorithmes. |
| Modèle | Représentation mathématique d’un problème qui permet de faire des prédictions ou classifications. |
La magie du Machine Learning réside dans sa capacité à traiter des volumes massifs de données, permettant ainsi aux entreprises de prendre des décisions informées plus rapidement et plus efficacement. Pour en savoir plus sur ces fondamentaux, des ressources comme DataScientest proposent des lectures approfondies.
Les types de Machine Learning : une plongée dans les techniques
Dans le vaste océan du Machine Learning, trois grands courants se dessinent : l’apprentissage supervisé, non supervisé et par renforcement. Chacun de ces types a des caractéristiques uniques et des applications adaptées.
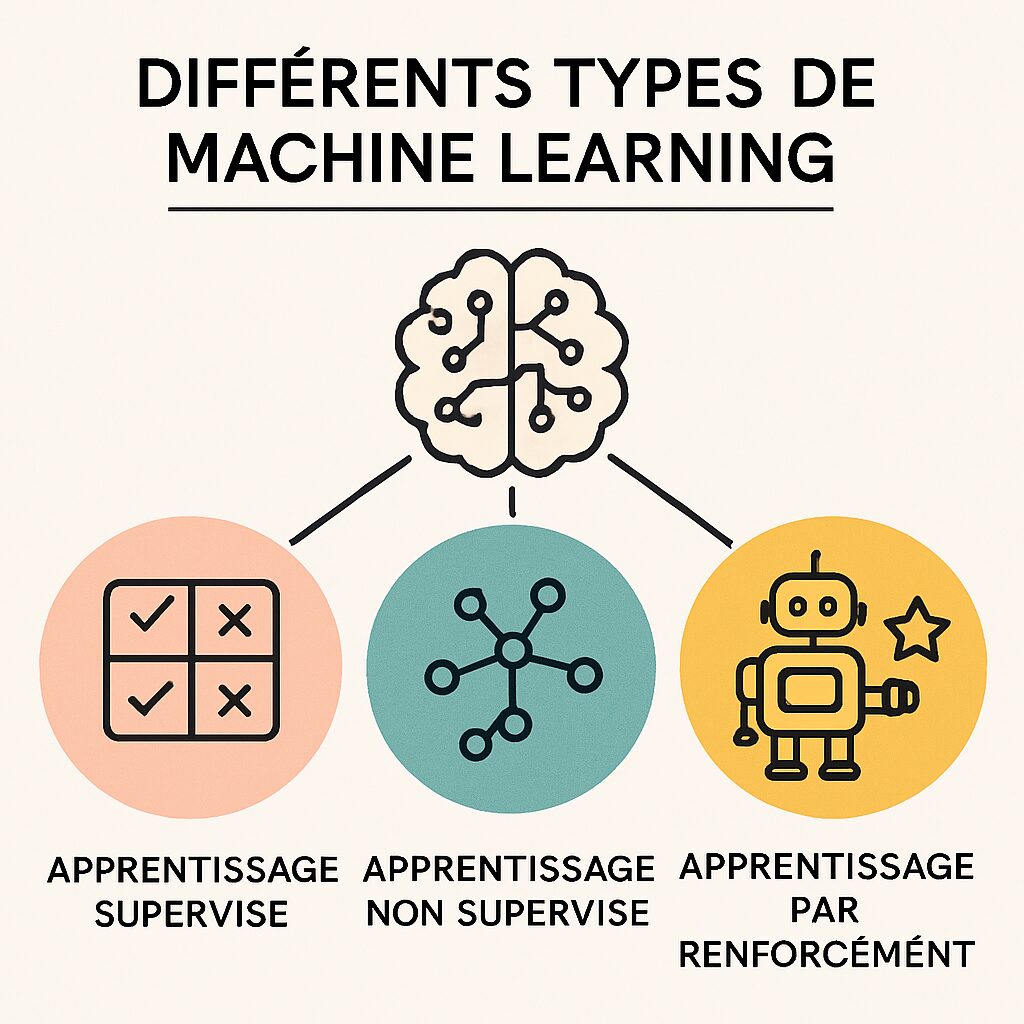
L’apprentissage supervisé : navigation guidée avec des données étiquetées
Dans l’apprentissage supervisé, le modèle est doté d’un ensemble de données préalablement étiquetées. Il apprend à partir d’exemples concrets, ce qui le rend très efficace pour des tâches comme la classification ou la régression. Par exemple, un ensemble de données pourrait contenir des photos d’animaux, avec des étiquettes indiquant « chien », « chat », etc. Le modèle s’entraîne à reconnaître ces catégories.
Les algorithmes de régression font partie des plus connus, utilisés par exemple pour prédire les ventes d’un produit en fonction de différents paramètres comme le prix et la saisonnalité. L’un des plus puissants de cette catégorie, le Keras, est souvent employé par les data scientists pour développer simplement et rapidement des réseaux de neurones profonds.
- Exemples d’utilisation :
- Prévisions financières
- Détection des spams dans les emails
- Analyse des sentiments dans les commentaires en ligne
Cependant, il existe quelques défis, notamment le coût de l’étiquetage des données et le risque de biais si les données utilisées pour l’entraînement ne sont pas représentatives. Les entreprises comme IBM Watson et Microsoft Azure ML excellent dans l’optimisation de ces systèmes.
L’apprentissage non supervisé : découvrir des motifs cachés
À l’opposé, l’apprentissage non supervisé explore des ensembles de données sans étiquettes. Il cherche exclusivement à trouver des motifs sous-jacents dans les données. C’est là que réside la force des algorithmes comme K-means, qui segmentent les données en groupes de similarités.
Par exemple, une entreprise de e-commerce peut utiliser le clustering pour mieux comprendre les habitudes d’achat de ses clients, en déclinant ces données en segments. Imaginez une plateforme comme Amazon qui groupe des utilisateurs similaires pour personnaliser l’expérience d’achat et les recommandations de produits !
- Exemples d’utilisation :
- Segmentation de marché
- Analyse d’image et classification
- Détection d’anomalies dans les systèmes de sécurité
Ce type d’apprentissage est à la pointe des recherches grâce à ses capacités à traiter des volumes colossaux de données sans nécessité d’étiquetage préalable, ce qui le rend très utile dans des domaines comme la cybersécurité. Les outils tels que DataRobot ou H2O.ai intègrent également ces techniques dans leurs offres.
L’apprentissage par renforcement : apprendre par essais et erreurs
L’apprentissage par renforcement se distingue des autres types en se concentrant sur des agents qui prennent des décisions dans un environnement donné pour maximiser une récompense. AlphaGo, l’IA qui a surpassé le champion de Go, en est un exemple emblématique. Ici, le modèle explore différentes actions jusqu’à ce qu’il découvre la meilleure stratégie.
Dans un scénario typique, l’algorithme reçoit des récompenses pour ses choix réussis et des pénalités pour les échecs. Cela renforce certains comportements à travers des cycles d’apprentissage continus. Ces systèmes sont appliqués pour former des robots à naviguer dans des environnements complexes ou à jouer à des jeux vidéo.
- Exemples d’utilisation :
- Jeux vidéo (Dota 2, StarCraft)
- Contrôle de drones autonomes
- Systèmes de recommandation adaptative
Ce type est captivant car il pousse les systèmes à apprendre de manière dynamique, ce qui crée des applications toujours plus impressionnantes. Les frameworks TensorFlow et PyTorch sont deux des outils les plus populaires pour développer ces agents intelligents.
| Type de Machine Learning | Description | Exemples d’Algorithmes |
|---|---|---|
| Supervisé | Données étiquetées pour des tâches de classification ou de régression. | Keras, Scikit-learn, IBM Watson |
| Non supervisé | Aucune étiquette, à la recherche de motifs cachés. | K-means, Apriori |
| Par renforcement | Apprendre à partir de l’interaction avec l’environnement. | Deep Q-Learning, AlphaGo |
Applications du Machine Learning dans le monde réel
Le Machine Learning s’est implanté dans un large éventail de domaines, allant de l’automobile à la santé. Il n’est pas seulement une technologie d’avenir, mais bien une composante essentielle de notre quotidien moderne. Les entreprises de tous horizons adoptent ces modèles d’IA pour tirer parti des données afin d’offrir des services personnalisés et innovants.
Les systèmes de recommandation sur des plateformes comme Netflix et YouTube exploitent le Machine Learning pour suggérer du contenu à leurs utilisateurs, transformant ainsi l’expérience de visionnage. Les algorithmes analysent les comportements antérieurs, tels que les films vus ou les vidéos likées, pour prédire ce qui pourrait en intéresser chacun. De même, les assistants personnels tels que Siri et Alexa reposent sur le traitement du langage naturel, une application du Machine Learning qui interprète les requêtes vocales pour répondre de manière pertinente.
Le secteur de la santé profite également de manière significative. L’utilisation des algorithmes d’apprentissage machine permet aux médecins d’identifier plus rapidement les cas de maladies à partir d’images médicales et de données patient. De plus, des entreprises comme AIBM Watson développent des outils qui aident à la prise de décisions cliniques.
- Commerce : recommandations de produit personnalisées.
- Santé : diagnostic et détection précoce des maladies.
- Automobile : véhicules autonomes utilisant des réseaux de neurones pour la navigation.
- Finance : détection de fraudes et évaluation des risques.
Pour approfondir ces applications concrètes, des ressources comme Coursera offrent de nombreux cours en ligne sur le sujet.
Machine Learning et analyse prédictive : un duo gagnant
Les analyses prédictives s’appuient sur le Machine Learning pour faire des prévisions basées sur des données historiques. Le risque dans ce type d’analyse est de se baser sur des modèles qui peuvent être biaisés, ce qui peut occasionner des prévisions erronées. Les entreprises recherchent souvent à optimiser leurs performances grâce à des recommandations et des prédictions adaptées.
La capacité de Scikit-learn à automatiser la création de modèles analytiques permet une intervention rapide face aux besoins d’analyse des données. Cela transforme dorénavant les méthodes de prise de décision. Par exemple, des chaînes de magasins utilisent le Machine Learning pour prévoir les ventes des produits en fonction des tendances et comportements d’achat. Elles peuvent alors ajuster leurs stocks pour répondre à la demande anticipée.
- Rôle des Data Scientists : En intégrant des modèles d’apprentissage, ils connectent les points entre les données et les décisions stratégiques.
- Outils d’analyse : Les plateformes comme Google AI ou Amazon SageMaker proposent des solutions accessibles pour intégrer ces pratiques d’analyse prédictive dans les entreprises.
Les algorithmes de détection d’anomalies, par exemple, sont utilisés dans le domaine de la cybersécurité pour repérer des comportements suspects qui pourraient indiquer des fraudes ou piratages. Ces modèles apprennent à identifier des comportements normaux et à détecter les écarts dans les activités.
| Domaine d’application | Exemples d’utilisation |
|---|---|
| Commerce | Prévisions de vente, recommandations personnalisées. |
| Santé | Diagnostic d’images, prédictions de maladies. |
| Finance | Évaluation de risque, détection de fraude. |
L’avenir du Machine Learning et son rôle dans la transformation numérique
En regardant vers l’avenir, le rôle du Machine Learning ne fera que se renforcer à mesure que les entreprises adoptent des solutions basées sur l’IA. Avec l’essor du Big Data, les techniques de machine learning deviendront cruciales pour extraire des informations précieuses de véritables océans de données. Les applications désigneront des domaines jusqu’alors inexplorés, propices à créer de nouvelles approches innovantes.
La convergence entre l’IA et d’autres technologies comme la blockchain va également modifier considérablement la manière dont les entreprises fonctionnent. Les algorithmes d’apprentissage machine seront intégrés dans les processus d’affaires, augmentant l’efficacité et réduisant les coûts.
En conclusion, alors que les modèles d’IA et de Machine Learning continuent de mûrir, les possibilités deviendront infinies, et les défis, des opportunités d’apprentissage. Des entreprises innovantes, comme H2O.ai, se positionnent déjà sur ce marché dynamique pour exploiter ces tendances et transformer les modèles d’affaires.
Pour plonger plus profondément dans ces innovations et leurs implications, consulter des experts ou suivre les dernières recherches pourra s’avérer bénéfique. N’oubliez pas que le monde du Machine Learning est toujours en évolution et nécessite un apprentissage constant.